Mục lục bài viết || Contents of the article
Khép lại chủ đề Những lưu ý khi phân tích ứng dụng Window chuyên gia an ninh mạng Nguyễn Việt Anh tiếp tục gửi đến các bạn những lưu ý khi phân tích: Các luồng tiến trình, Phối hợp đa tiến trình với các Mutex, Các Service, Mô hình COM (Component Object Model), Kernel Mode và User Mode, Native API trong bài viết dưới đây.
Các luồng tiến trình
Tiến trình được coi là vỏ bọc chứa trình thực thi, các luồng tiến trình mới chính là thứ được thực thi bởi Windows OS. Luồng tiến trình là các chuỗi độc lập chứa lệnh được thực thi bởi CPU, các luồng là song song, không luồng nào phải chờ luồng nào. Một tiến trình có một hoặc nhiều luồng, mỗi luồng thực hiện một phần code trong tiến trình. Các luồng trong cùng một tiến trình chia sẻ cùng một không gian bộ nhớ nhưng mỗi luồng được cấp phát những thanh ghi và stack riêng.
Thread context
Khi một luồng được chạy, nó có toàn quyền điều khiển CPU hoặc nhân CPU, các luồng khác sẽ không thể can thiệp vào trạng thái CPU/nhân CPU vào thời điểm đó. Khi một luồng thay đổi giá trị của một thanh ghi CPU, nó sẽ không làm ảnh hưởng tới các luồng khác. Trước đây, khi OS chưa có cơ chế quản lý luồng hiệu quả, mọi giá trị trong CPU được lưu trong một cấu trúc dữ liệu gọi là thread context. OS sau đó sẽ nạp thread context của luồng mới vào CPU và thực thi luồng mới đó.

Một ví dụ truy cập một biến cục bộ và push nó vào stack. Lệnh lea tại 0x004010DE truy cập biến esp+58h và lưu nó vào EDX, sau đó push EDX vào stack. Nếu một luồng khác thực thi code giữa hai lệnh trên, mà code đó lại thao tác trên EDX thì giá trị EDX đối với luồng ban đầu sẽ sai và luồng ban đầu của ta sẽ không còn chạy đúng nữa. Khi sử dụng cơ chế chuyển giữa các thread context, nếu một luồng khác chạy xen giữa hai lệnh này, giá trị của EDX đã được lưu trong thread context và khi luồng ban đầu thực hiện đến lệnh push (tại 0x004010E2), thread context của nó sẽ được khôi phục và EDX được khôi phục giá trị đúng với giá trị ban đầu của nó sau lệnh lea (tại 0x004010DE), nhờ đó mà không luồng nào có thể gây xung đột thanh ghi và cờ với các luồng khác.
Tạo một luồng
Hàm CreateThread được dùng để tạo một luồng mới. Hàm gọi đến sẽ chỉ định địa chỉ bắt đầu, thường là chỉ định bằng hàm start. Code thực thi sẽ bắt đầu tại địa chỉ bắt đầu và chạy cho đến khi hàm trả về; nếu luồng thực thi không cần trả về, nó sẽ chạy cho đến khi kết thúc tiến trình. Khi phân tích code gọi đến hàm CreateThread, ta cần phân tích cả hàm start để và toàn bộ phần code của hàm gọi đến CreateThread.
Mã độc có thể sử dụng hàm CreateThread theo nhiều cách, chẳng hạn:
- Sử dụng CreateThread để nạp một thư viện độc hại vào một tiến trình, với lời gọi hàm CreateThread cùng địa chỉ bắt đầu là địa chỉ của LoadLibrary. Tham số truyền vào CreateThread là tên của thư viện muốn nạp. DLL mới được nạp vào bộ nhớ của tiến trình và hàm DllMain được gọi.
- Tạo hai luồng mới cho dữ liệu vào và dữ liệu ra: Một luồng lắng nghe trên một socket hoặc pipe stream (kênh pipe), dữ liệu ra của luồng được truyền làm dữ liệu vào của tiến trình; một luồng đọc từ dữ liệu ra chuẩn của tiến trình và gửi chúng tới socket hoặc pipe stream. Mục đích của mã độc là gửi mọi dữ liệu vào cùng một socket hoặc một pipe stream để có thể truyền thông liên tục với ứng dụng đang chạy. Minh họa cho kỹ thuật này ở hình dưới.

Ta xác định hai lời gọi hàm CreateThread gần nhau. Tham số đầu vào của hai hàm này là các giá trị lpStartAddress (0x004016F9 và 0x0040171E), ta có thể nhìn vào các giá trị này để biết đoạn code nào sẽ được gọi đến khi hai luồng này thực thi. Để xác định mục đích của hai luồng này, ta chuyển hướng tới ThreadFunction1 trước. Hàm thực thi của luồng thứ nhất thực hiện một vòng lặp trong đó gọi hàm ReadFile để đọc từ một kênh pipe, sau đó chuyển hướng dữ liệu đầu ra của ReadFile vào một socket với lệnh send.

Hàm thực thi của luồng thứ hai thực hiện một vòng lặp gọi hàm recv để đọc mọi dữ liệu truyền qua mạng và chuyển hướng dữ liệu và một kênh pipe bằng hàm WriteFile.

Ngoài các luồng, Microsoft còn sử dụng các fiber. Fiber cũng giống như luồng, nhưng thay vì được quản lý bởi OS, chúng được quản lý bởi các luồng. Các fiber cùng chia sẻ một thread context.
Phối hợp đa tiến trình với các Mutex
Mutex ( trong UM), tương tự Mutant ( trong KM), là các đối tượng toàn cục (global object) giúp phối hợp đa tiến trình và đa luồng.
Các mutext được sử dụng chủ yếu để điều khiển truy cập tới các tài nguyên dùng chung, chúng cũng thường xuyên bị mã độc lợi dụng. Ví dụ, nếu hai luồng cùng muốn truy cập tới một cấu trúc nhớ, nhưng tại một thời điểm chỉ có một luồng được phép truy cập tới cấu trúc nhớ đó, một mutex có thể quản lý hai truy cập này.
Đối với một mutex, tại một thời điểm chỉ có một luồng được sở hữu nó. Các mutex khá quan trọng đối với chuyên gia phân tích mã độc vì chúng thường sử dụng tên được hard-coded, đó là các dấu hiệu hữu ích. Các mutex phải sử dụng tên được hard-coded vì tên mutex phải thống nhất nếu mutex đó được sử dụng chung bởi hai tiến trình mà hai tiến trình đó lại không giao tiếp với nhau thông qua bất cứ con đường nào khác.
Một luồng đạt quyền truy cập tới một mutex bằng cách gọi hàm WaitForSingleObject, tất cả các luồng đến sau muốn truy cập tới mutex đó thì sẽ phải chờ. Khi một luồng sử dụng xong một mutex, nó cần gọi hàm ReleaseMutex để giải phóng mutex.
Một mutex có thể được tạo với hàm CreateMutex. Một tiến trình có thể lấy handle từ mutex của một tiến trình khác thông qua lời gọi hàm OpenMutex. Mã độc thường tạo một mutex và gọi một mutex với tên của mutex vừa tạo để chắc chắn rằng chỉ có một bản mẫu của mã độc đó được chạy trong một thời điểm.
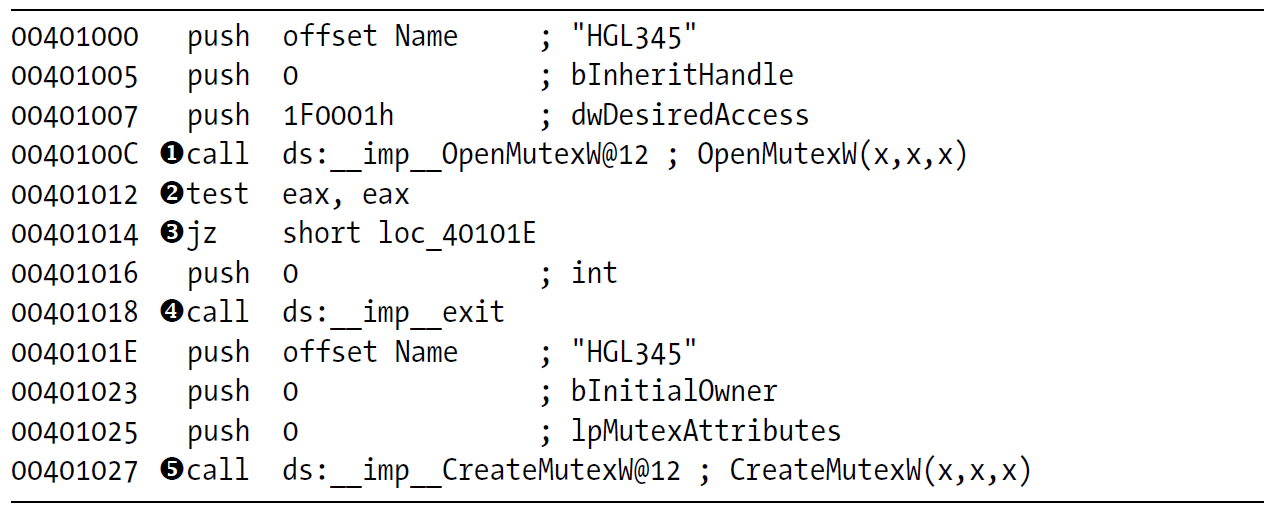
Trong ví dụ, mã độc sử dụng một mutex có tên hard-coded là HGL345. Đầu tiên nó gọi hàm OpenMutex để kiểm tra xem hệ thống đã tồn tại mutex có tên HGL345 chưa (dòng 0x0040100C). Nếu giá trị trả về của hàm OpenMutex là NULL (0x00401012), nó sẽ nhảy qua đoạn code tiếp theo (short loc_40101E) để tiếp tục thực thi. Nếu giá trị hàm OpenMutex khác NULL, mã độc gọi hàm exit để thoát (0x00401018).
Trong đoạn code shot loc_40101E, mã độc tạo một mutex với tên HGL345 (dòng 0x00401027) để đảm bảo bất cứ bản mẫu nào khác của nó cũng sẽ thoát khi chúng chạy tới đoạn code trong ví dụ này.
Các Service
Một cách khác để mã độc thực thi code bổ sung là cài đặt chính nó như một dịch vụ – service. Windows cung cấp cơ chế cho phép các tác vụ chạy mà không một cần tiến trình hay luồng nào bằng cách sử dụng các service như các ứng dụng chạy ngầm; code được lập lịch và thực thi dưới sự quản lý của Windows Service Manager.
Việc sử dụng service mang lại nhiều thuận tiện cho người viết mã độc. Các service thường chạy với quyền SYSTEM hoặc các đặc quyền tương tự. Với quyền SYSTEM, mã độc có toàn quyền điều khiển với mọi file trên một phân vùng NTFS. Các service cũng cung cấp một cách tốt để mã độc che giấu và duy trì sự tồn tại của mình trong hệ thống vì chúng có thể được cài đặt tự khởi động cùng OS và có thể không để lại dấu vết trên Task Manager như các tiến trình.
Để thu thập thông tin về các service đang chạy, ta có thể dùng Autoruns trong bộ công cụ SysInternal Suite.
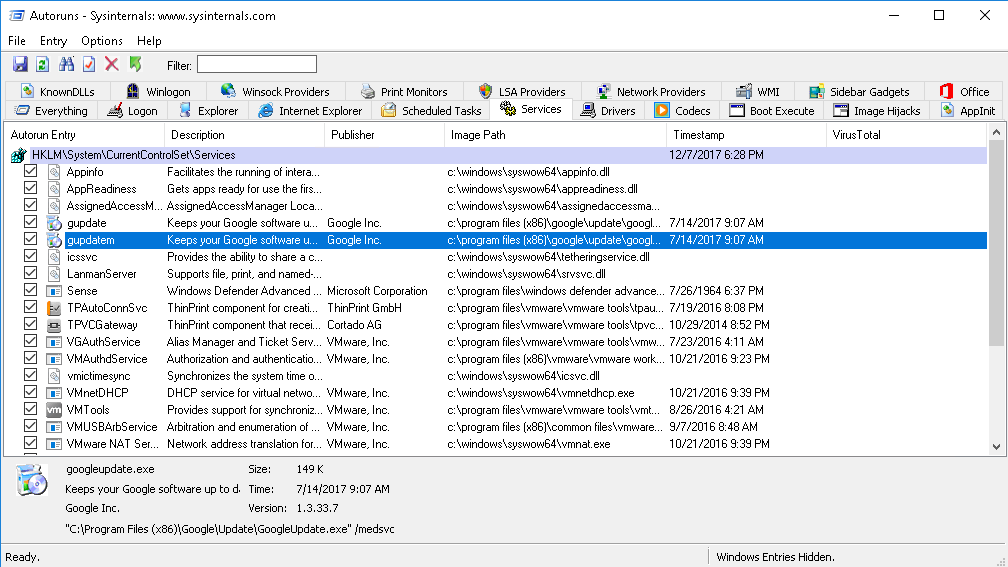
Các service có thể được cài đặt và quản lý bởi các hàm Windows API:
– OpenSCManager Trả về một handle tới trình quản lý điều khiển service (service control manager – SCM), handle này có thể được dùng cho mọi lời gọi hàm về sau liên quan đến service. Mọi loại code tương tác với các service đều phải gọi hàm này.
– CreateService Thêm một service vào trình quản lý điều khiển service, cho phép hàm gọi đến chỉ định service tự khởi động cùng hệ thống hoặc khởi động thủ công.
– StartService Khởi động một service, hàm này chỉ được sử dụng khi service được cài đặt khởi động thủ công.
Windows hỗ trợ một số dạng service khác nhau, thực thi theo các cách khác nhau. Phổ biến nhất đối với mã độc là service dạng WIN32_SHARE_PROCESS, service dạng này lưu trữ code trong một DLL và kết hợp một vài service khác nhau trong cùng một tiến trình dùng chung. Trong Task Manager, ta có thể tìm thấy các tiến trình có tên svchost.exe, chính là những tiến trình chạy các service WIN32_SHARE_PROCESS.
Service kiểu WIN32_OWN_PROCESS cũng thường được dùng, chúng lưu code thực thi trên một file .exe và được chạy như một tiến trình độc lập.
Loại service phổ biến cuối cùng là KERNEL_DRIVER, được sử dụng để nạp code thực thi vào kernel.
Thông tin về các service trên một máy local được lưu trong registry. Mỗi service có một subkey trong HKLM\SYSTEM\CurrentControlSet\Services. Ví dụ sau minh họa cho các registry entry của HKLM\SYSTEM\CurrentControlSet\Services\VMware Physical Disk Helper Service.
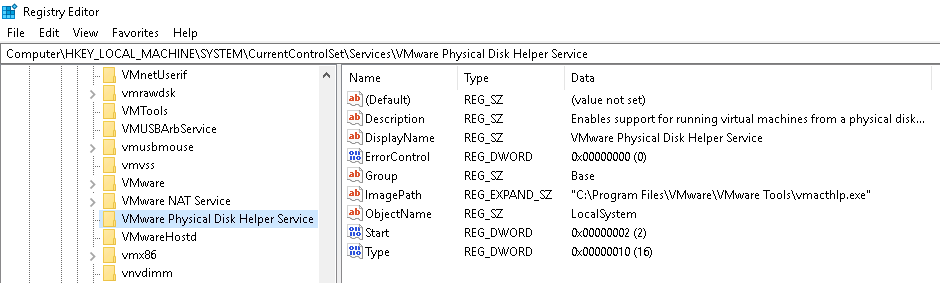
Code thực thi của service VMware Physical Disk Helper được lưu trong C:\Program Files\VMware\VMware Tools\vmacthlp.exe. Giá trị kiểu service (Type) là 0x10, ứng với WIN32_OWN_PROCESS và giá trị loại khởi động (Start) là 0x02 tương ứng với AUTO_START.
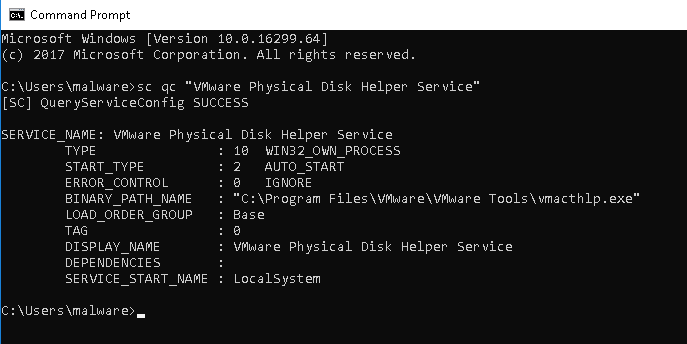
Công cụ SC tích hợp sẵn trong Windows hỗ trợ ta khám phá và quản lý các service. Công cụ này bao gồm các lệnh để thêm, xóa, khởi động, dừng và truy vấn các service. Ví dụ, lệnh qc cho phép truy vấn các tùy chọn cấu hình của một service bằng cách truy cập tới các thông tin trong registry tương tự như minh ví dụ phía trên, nhưng hiển thị chúng ở dạng dễ đọc hơn.
Mô hình COM (Component Object Model)
COM là một chuẩn giao diện giúp các thành phần phần mềm khác nhau có thể gọi tới code của nhau mà không cần biết về nhau. Khi phân tích những mã độc sử dụng COM, ta cần xác định đoạn code nào được chạy xuất phát từ một lời gọi hàm COM.
COM hoạt động với tất cả các ngôn ngữ lập trình và được thiết kế để hỗ trợ các thành phần phần mềm tái sử dụng được với mọi chương trình. COM sử dụng một kiến trúc đối tượng hoạt động đặc biệt tốt với các ngôn ngữ lập trình hướng đối tượng (nhưng nó không chỉ thiết kế dành riêng cho các ngôn ngữ hướng đối tượng). Nói một cách dễ hiểu hơn thì COM là một giao diện đứng ở giữa (giống như một thông dịch viên) để cho 2 components viết bằng 2 ngôn ngữ khác nhau có thể hiểu nhau.
Do tính linh hoạt của mình, COM phổ biến trong cả OS và các ứng dụng của Microsoft cũng như phần mềm của bên thứ ba. Mã độc sử dụng COM sẽ trở nên khó phân tích.
COM được triển khai dưới hình thức client/server framework. Các client là những chương trình tận dụng các COM object, còn server là các thành phần phần mềm tái sử dụng được (hay chính là các COM object). Microsoft cung cấp số lượng lớn các COM object để các chương trình sử dụng.
Mỗi thread sử dụng COM đều phải gọi hàm OleInitialize hoặc hàm CoInitializeEx ít nhất một lần trước khi gọi bất cứ hàm thư viện COM nào khác. Chuyên gia phân tích mã độc có thể tìm kiếm hai hàm này để xác định khi nào một chương trình sử dụng COM. Tuy nhiên, ngay cả khi đã biết một mẫu mã độc sử dụng một COM object như là một client, ta cũng không có nhiều thông tin hữu ích vì các COM object rất phong phú và phổ biến. Một khi đã xác định được chương trình sử dụng COM, ta cần tìm ra các thông tin nhận dạng object được sử dụng để tiếp tục phân tích.
Trong phần này còn nhiều khái niệm tôi chưa kịp trình bày trong mục này (CLSID, IID, Cách sử dụng COM Object…). Xin hẹn các bạn vào 1 bài sau.
Kernel Mode và User Mode
Windows cung cấp hai mức quyền truy cập bộ vi xử lý là kernel mode và user mode. Tất cả các hàm đã đề cập ở phần trước đều là các hàm user mode nhưng trong kernel mode, mọi thứ diễn ra theo cơ chế tương tự.
Gần như mọi loại code đều chạy trong user mode, ngoại trừ OS và các driver phần cứng (các file .sys trong C:\Windows\System32\drivers) chạy trong kernel mode. Trong user mode, mỗi process sở hữu không gian bộ nhớ riêng, tài nguyên và quyền truy cập riêng. Nếu một chương trình user mode thực thi một lệnh không hợp lệ và bị crash, Windows có thể thu hồi mọi tài nguyên và kết thúc chương trình đó.
Thường thì chương trình user mode không thể truy cập trực tiếp tới các thiết bị phần cứng, và chúng bị giới hạn với một tập con trong tất cả các thanh ghi và lệnh vi xử lý. Để quản lý phần cứng và thay đổi trạng thái kernel mode khi đang ở user mode, ta phải dựa vào các Windows API.
Khi ta gọi một hàm Windows API quản lý các cấu trúc của kernel mode, hàm đó sẽ tạo một lời gọi tới kernel. Trong code dịch ngược, sự xuất hiện các lệnh SYSENTER, SYSCALL hoặc INT 0x2E là dấu hiệu của một lời gọi tới kernel. Do không thể nhảy trực tiếp từ user mode tới kernel mode, các lệnh này sử dụng các bảng tra cứu (Lookup table) để định vị các hàm định nghĩa trước sẽ được chạy trong kernel.
Mọi process chạy trong kernel mode đều dùng chung tài nguyên hệ thống và địa chỉ bộ nhớ. Code chạy trong kernel mode thường thực hiện ít thao tác kiểm tra bảo mật hơn so với code chạy trong user mode và một khi chúng thực thi một lệnh không hợp lệ, OS sẽ không thể chạy tiếp, gây ra các lỗi Windows Blue screen of Death.
Code chạy trong kernel mode có thể quản lý code trong user mode, nhưng code trong user mode chỉ có thể quản lý ngược lại code trong kernel mode thông qua một số API cụ thể. Mặc dù mọi code chạy trong kernel mode dùng chung bộ nhớ và tài nguyên hệ thống, tại một thời điểm luôn chỉ có một process context được hoạt động.
Hiểu biết về kernel mode mang lại quyền năng cho người viết mã độc. Nhiều thao tác chỉ có thể được thực hiện trong kernel mode. Hầu hết các chương trình bảo mật như AV hoặc firewall đều chạy trong kernel mode để có thể truy cập và giám sát hoạt động của mọi ứng dụng chạy trên hệ thống. Mã độc chạy trong kernel mode có thể qua mặt AV và các firewall.
Trong kernel mode, mọi khác biệt giữa các process chạy với đặc quyền hay không có đặc quyền đều được loại bỏ. Ngoài ra, các tính năng kiểm soát của OS đều không được áp dụng trên kernel. Vì các lí do này, gần như mọi rootkit đều sử dụng code chạy trong kernel.
Phát triển code cho kernel mode khó hơn nhiều so với code cho user mode. Một rào cản lớn là kernel code dễ gây crash hệ thống trong quá trình phát triển và debug. Ngoài ra, nhiều hàm phổ biến lại không sử dụng được trong kernel mode, các công cụ hỗ trợ lập trình và biên dịch trong kernel code cũng không nhiều. Do các trở ngại trên, chỉ các mã độc tinh vi mới chạy trong kernel mode và đa số mã độc phổ biến đều không có thành phần kernel.
Native API
Native API là giao diện mức thấp để tương tác với Windows và hiếm khi được sử dụng bởi các chương trình vô hại nhưng lại phổ biến đối với mã độc. Các lời gọi hàm Native API có thể qua mặt các hàm Windows API bình thường.
Khi ta gọi một hàm trong Windows API, hàm đó thường không trực tiếp thực hiện chức năng được yêu cầu vì hầu hết các cấu trúc dữ liệu quan trọng đều được đặt trong kernel và không thể được truy cập từ bên ngoài kernel. Microsoft đã tạo một tiến trình nhiều bước giúp các chương trình user mode thực hiện được chức năng yêu cầu.
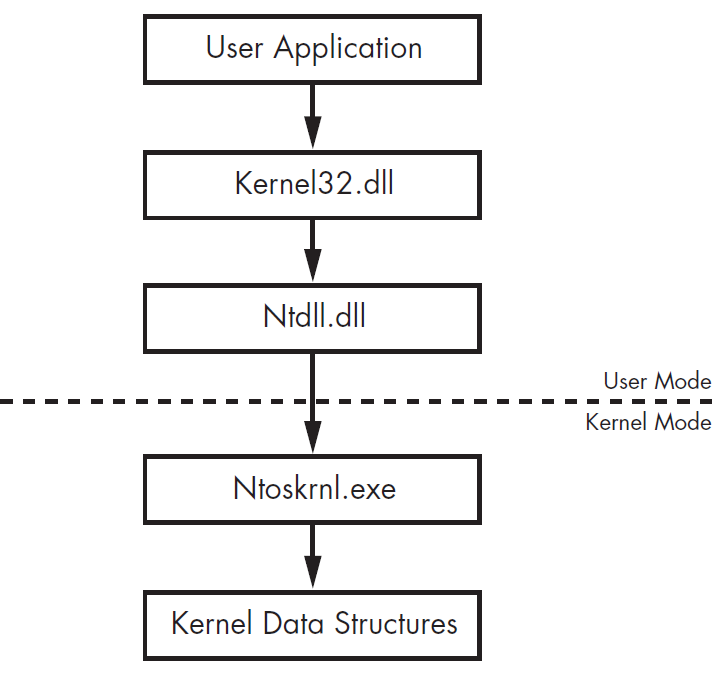
Các ứng dụng người dùng (chương trình user mode) được cấp phép truy cập tới các user API trong kernel32.dll và một số DLL khác, tất cả chúng cùng gọi tới ntdll.dll, đây là một DLL đặc biệt thực hiện quản lý các tương tác giữa không gian user và kernel. Các hàm chức năng trong kernel thường được đặt trong ntoskrnl.exe. Tiến trình chuyển đổi này khá phức tạp nhưng là cần thiết vì với các API kernel và user mode riêng rẽ, Microsoft có thể thay đổi kernel mà không gây ảnh hưởng tới các ứng dụng trong user mode.
Các hàm ntdll được gọi là Native API, chúng sử dụng các API và cấu trúc giống như trong kernel mode. Các chương trình bình thường không gọi được đến Native API nhưng Windows không có cơ chế ngăn cản chúng gọi đến Native API.
Microsoft không công khai tài liệu chi tiết về Native API, ta có thể nghiên cứu chúng qua cuốn Windows NT/2000 Native API Reference by Gary Nebbett (Sams,
2000) (hơi cũ nhưng vẫn dùng tốt) hoặc http://undocumented.ntinternals.net/
Rất nhiều hành vi được thực hiện bằng cách gọi hàm trong Native API mà không có hàm Windows API nào tương ứng. Gọi trực tiếp Native API cho phép mã độc thực hiện được những hành vi mà các chương trình bình thường không thể thực hiện. Ngoài ra, việc gọi hàm Native API ít để lại dấu vết hơn so với gọi hàm Windows API. Nhiều chương trình AV hoặc phần mềm bảo mật thực hiện giám sát các lời gọi hệ thống (system call) tạo bởi một process. Nếu process này gọi trực tiếp một hàm Native API, nó có thể qua mặt các chương trình AV này.
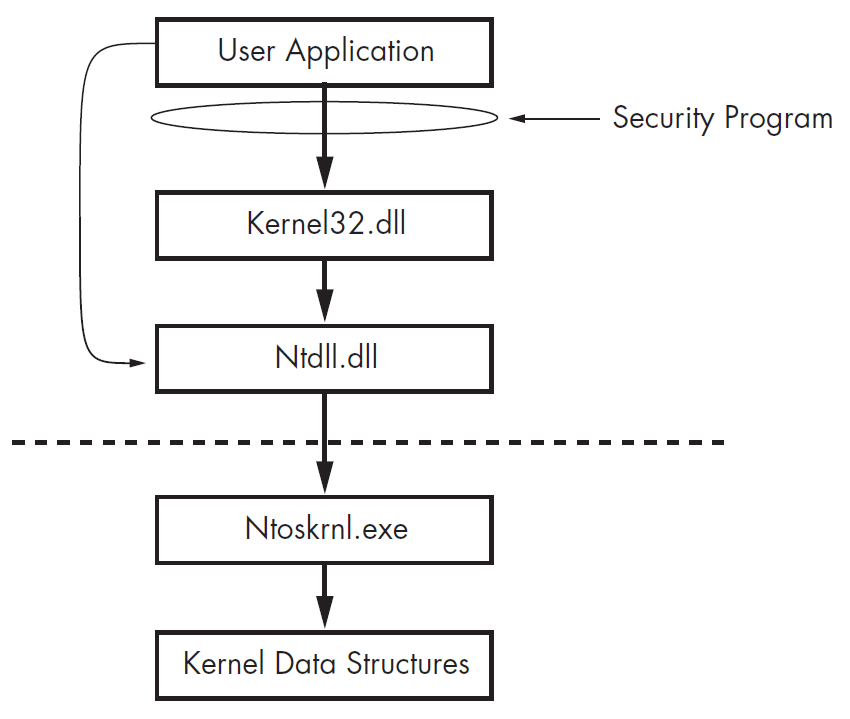
Sơ đồ bên dưới minh họa một chương trình bảo mật được thiết kế không tối ưu, thực hiện giám sát các lời gọi đến kernel32.dll. Để qua mặt chương trình này, mã độc thực hiện gọi trực tiếp tới Native API. Thay vì gọi các hàm Windows API như ReadFile hay WriteFile, mã độc gọi các hàm NtReadFile và NtWriteFile, đó là các hàm của ntdll.dll và không bị giám sát bởi chương trình bảo mật. Một chương trình bảo mật được thiết kế tốt phải giám sát các lời gọi tại tất cả các mức, bao gồm cả kernel, để ngăn chặn những chiến thuật như trong ví dụ này.
Có nhiều nhóm hàm Native API được dùng để lấy thông tin hệ thống, thông tin các process, thread, handle và các đối tượng khác, các hàm này bao gồm: NtQuerySystemInformation, NtQueryInformationProcess, NtQueryInformationThread, NtQueryInformationFile, và NtQueryInformationKey. Chúng cung cấp nhiều thông tin chi tiết hơn so với các hàm Win32.
Một hàm Native API khác cũng phổ biến đối với mã độc là NtContinue. Hàm này được dùng để trả về từ một ngoại lệ, tức là nó giúp chuyển luồng thực thi (flow, phân biệt với luồng tiến trình) trở về luồng thực thi chính sau khi một ngoại lệ được xử lý. Tuy nhiên, vị trí để trả về phụ thuộc vào từng hoàn cảnh ngoại lệ. Mã độc thường dùng hàm này để chuyển luồng thực thi một cách phức tạp nhằm gây rối cho các chuyên gia phân tích và khiến chương trình khó debug hơn.
Trong một số trường hợp, chẳng hạn bảng export của ntdll.dll, cùng một hàm có thể có tên với tiền tố Nt hoặc Zw, ví dụ NtReadFile và ZwReadFile. Trong không gian user, các hàm này thực hiện cùng một chức năng và thường gọi đến cùng một code. Trong kernel mode, đôi khi chúng có một vài khác biệt nhỏ, nhưng khi phân tích mã độc, ta có thể bỏ qua những khác biệt nhỏ này.
Các chương trình Native (Native applications) là các chương trình không dùng Win32 subsystem mà chỉ gọi các hàm Native API. Kiểu chương trình này không phổ biến đối với mã độc nhưng gần như không bao giờ là một chương trình không độc hại. Thông tin subsystem trong PE header cho ta biết một chương trình có phải là chương trình native hay không.
XEM THÊM: Top 3 chứng chỉ mạng giá trị nhất ngành quản trị mạng


